
 Tweet
Tweet
Benchmarking vs threadripper is a bit wierd since this part is not in the same market at all, a benchmark against mi300a would be more interesting. Also afaik in contrast to the mi300a GH is not uma and the cpu side has no direct access to hbm.
-
-
I believe this is correct - which is why I'm skeptical of Michael's assertion that Grace's wins are due to HBM3.Originally posted by DiamondAngle View PostComment
-
We went through this topic in comment thread of the last set of Grace benchmarks. GPTshop.ai believes Linux is allocating and using the GPU-attached HBM for CPU workloads, while I do not. I don't know of a way to conclusively determine that it is not, however. If anyone knows of a way, please speak up!Originally posted by Dawn View Post
The article is testing two ThreadRipper models. The non-Pro models have only 4 memory channels (i.e. 256-bit datapath) enabled. The Pro model has 8 enabled (i.e. 512-bit). Neither support the full 12-channel, 768-bit datapath of the EPYC 9004 models.Originally posted by Dawn View Post
It's cache-coherent, although the OS still needs to map pages into process address space, obviously.Originally posted by Dawn View Post
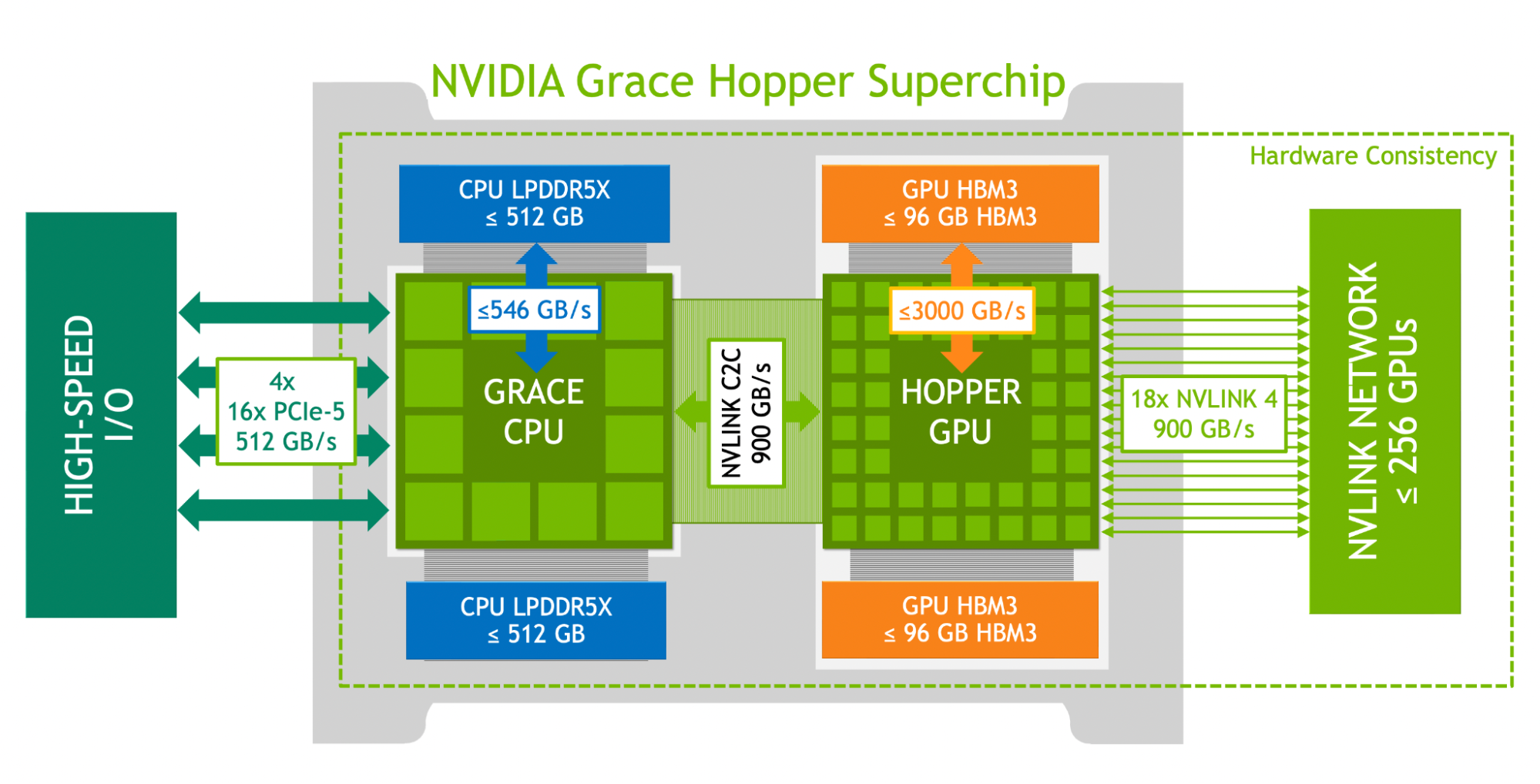
Nvidia claims there's 450 GB/s of NVLink bandwidth, in each direction, between the two.
Good idea! Although the above diagram shows 546 GB/s of memory bandwidth to the LPDDR5X, I think I've seen newer docs which claim it's good for only 480 GB/s. Anyway, more than 550 would be a clear indicator of the claimed HBM usage.Originally posted by Dawn View PostComment
-
The performance/cost comparisons are extremly unfair, because of 40k total for the GH200, 30k is the H100 and Grace CPU is less than 10k.Last edited by GPTshop.ai; 20 February 2024, 02:39 PM.Comment
-
Agreed on most points. I mentioned Epyc mainly because the "HBM" thing got brought up in the other article too - I just didn't have the energy to comment on it.Originally posted by coder View Post
My assumption, which is possibly a bad one, would be that the GPU memory space - while coherent - would be owned by the Nvidia driver and reserved for cudaMalloc() calls and similar, as well as whatever on-device housekeeping and program memory are needed. You could pass pointers between the CPU and GPU, but "regular ol' host malloc() allocates in the GPU address range" sounds super weird to me.
Either STREAM or lmbench should make it pretty clear.Comment
-
Why not choosing a more mature platform for competition (a AMD Epyc 9754 is at ~5700€ - not sure about the rest but there is a lot of space till 30-40k €)? Not ever test is covered by the tested AMD EPYC 9754 (128-Core, 12 Memory Channels), but differences because of the memory bandwidth are reduced: https://openbenchmarking.org/vs/Proc...rse-V2+72-CoreComment
-
I find the results of these benchmarks very contusing, specifically the NAS Parallel Benchmarks.
We have a 96C/192T 8 channel TR being twice as fast as a 64C/128T 4 channel TR and this latter system being effectively tied with the GH200.
How is this possible? I know people will say it's thanks to all the extra memory bandwidth that the TR Pro has over the non-Pro TW, but that doesn't explain with the NVIDIA chip that's all about bandwidth should also be so far behind.
I think what is actually being benchmark here is the software and OS and not the hardware.
The reality is that ARM is a RISC ISA and x86 is primarily CISC and we don't know how well Ubuntu is optimized for ARM, we don't know how well the various pieces of software are optimized for ARM and frankly I believe that the level of optimization is all over the place, as evidenced by the fact that in some memory bandwidth intensive benchmarks the GH200 wins handily and in some it gets crushed.
If course on could argue that at the end of the day it doesn't matter because if you need to run a certain workload today, potential performance does not matter, actual performance does.
Still i would like to see how this performs with custom code, not canned benchmarks.Comment
-
It might be possible to disable most of the HBM with badram, rerun the test and see if the results are similar or not.Originally posted by coder View Post
Comment
-
CORRECTION: I thought about it again, GPTshop.ai will offer some absolutely crazy stuff ASAP. With crazy, I mean up to 8x Superchip (GH200 or Grace-Grace) in one case.Originally posted by GPTshop.ai View PostLast edited by GPTshop.ai; 20 February 2024, 06:02 PM.Comment
-
Very interesting results. What matters to me is the memory-bound benchmarks. My workloads require a lot of memory bandwidth. But I don't have much use of the GPU. It would be interesting to compare the GH200 to a Grace+Grace machine.Comment
Comment