If this is your first visit, be sure to
check out the FAQ by clicking the
link above. You may have to register
before you can post: click the register link above to proceed. To start viewing messages,
select the forum that you want to visit from the selection below.
Announcement
Collapse
No announcement yet.
Apple Launches The M2 Pro & M2 Max + New Mac Mini With M2 / M2 Pro
As far as I can tell, the in-package thing is mostly about saving space and maybe a little power. Otherwise, it seems to be the same 6200 MT/s LPDDR5 that you could have on DIMMs.
The big difference is that laptop CPUs almost never have more than 128-bit memory bus, whereas the M2 Pro and Max clearly do. That's their "trick" for reaching the big bandwidth numbers.
Do you just make this stuff up? ...if not, maybe you should think twice before you continue reading wherever you saw it.
There are LPDDR5-5200 SO-DIMMs on the market today, and I fully expect we'll see 6200 by the time Meteor Lake launches.
CAMM. Interestingly, it scales up to 256-bit, from what I've read. I just wonder when we'll see a laptop CPU that supports it... or maybe they're planning to use power-limited Xeon W models, in some "mobile workstation" laptops.
As far as YOU can tell? And yet you complain that other people are "just making things up"!!!
Have you read my technical discussions of M1, including details of how M1 memory system works? Uhh...
There is a LOT more going on there than you can possibly imagine, starting with characterization of each DIMM in the factory, which is then burned into a ROM on the SoC and used to optimize the voltage and refresh rates applied to each DIMM.
The issue is not that the DIMMs are run at a higher frequency when on the package, it is that they
- use less energy (lower wire capacitance) -- this is obvious
- they can be characterized and that characterization aggressively exploited (this is much less obvious)
It also helps that Apple appears to have vastly superior memory controllers to Intel. I've no idea why, but the bandwidth differences between Apple and Intel are stunning. Intel get slightly lower latency at the cost of vastly lower bandwidth, and overall it seems like they're making sub-optimal tradeoffs.
I have an M1 max 14 inch and it compiles code 7-10x faster than my previous AMD 8 core/16 thread Thinkpad.
This can't be true. Not if you're using the exact same compiler & version, targeting the same ISA, and using the same options.
Michael has run various benchmarks on the M1, over the past couple years -- both running Linux and MacOS -- and we've never seen anything remotely close to what you claim.
Well, once they start shipping, presumably the Ali Express links will be fixed/updated. Can you buy stuff from Ali Express, where you are?
Austria, AliExpress doesn't deliver here since 2023, because of a new "Packaging Act" that took effect.
As I understand, similar laws will/have been enabled in the eu, so probably this is just a mess-up or oversight (did not grease the right gears?)
Sure, they get lower latency as well. Scaling up the lines is more complicated the longer they are.
(Dram is not a serial, differential connection like pcie)
Nice idea, but the vast majority of DRAM latency doesn't seem to result from path length.
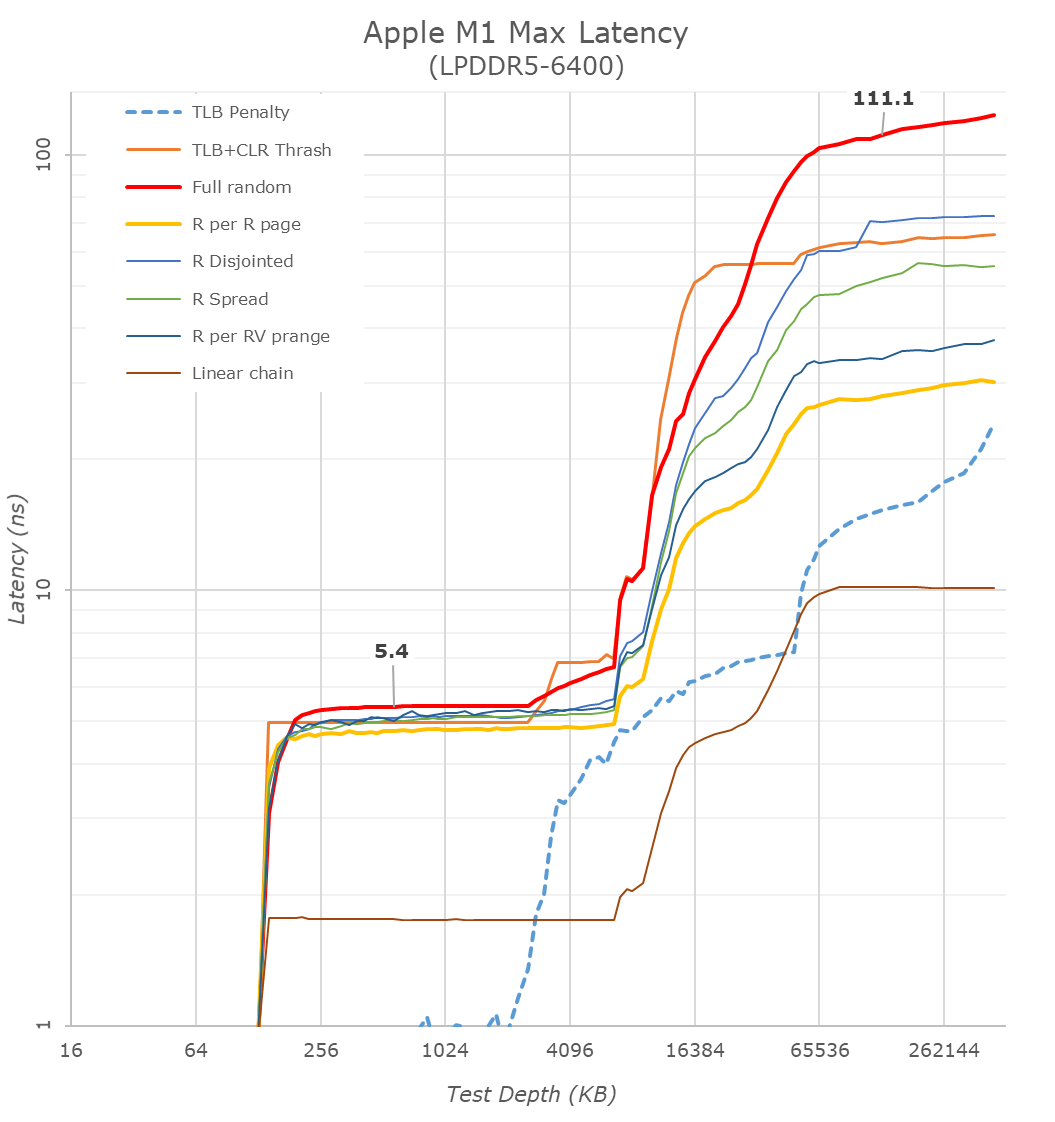
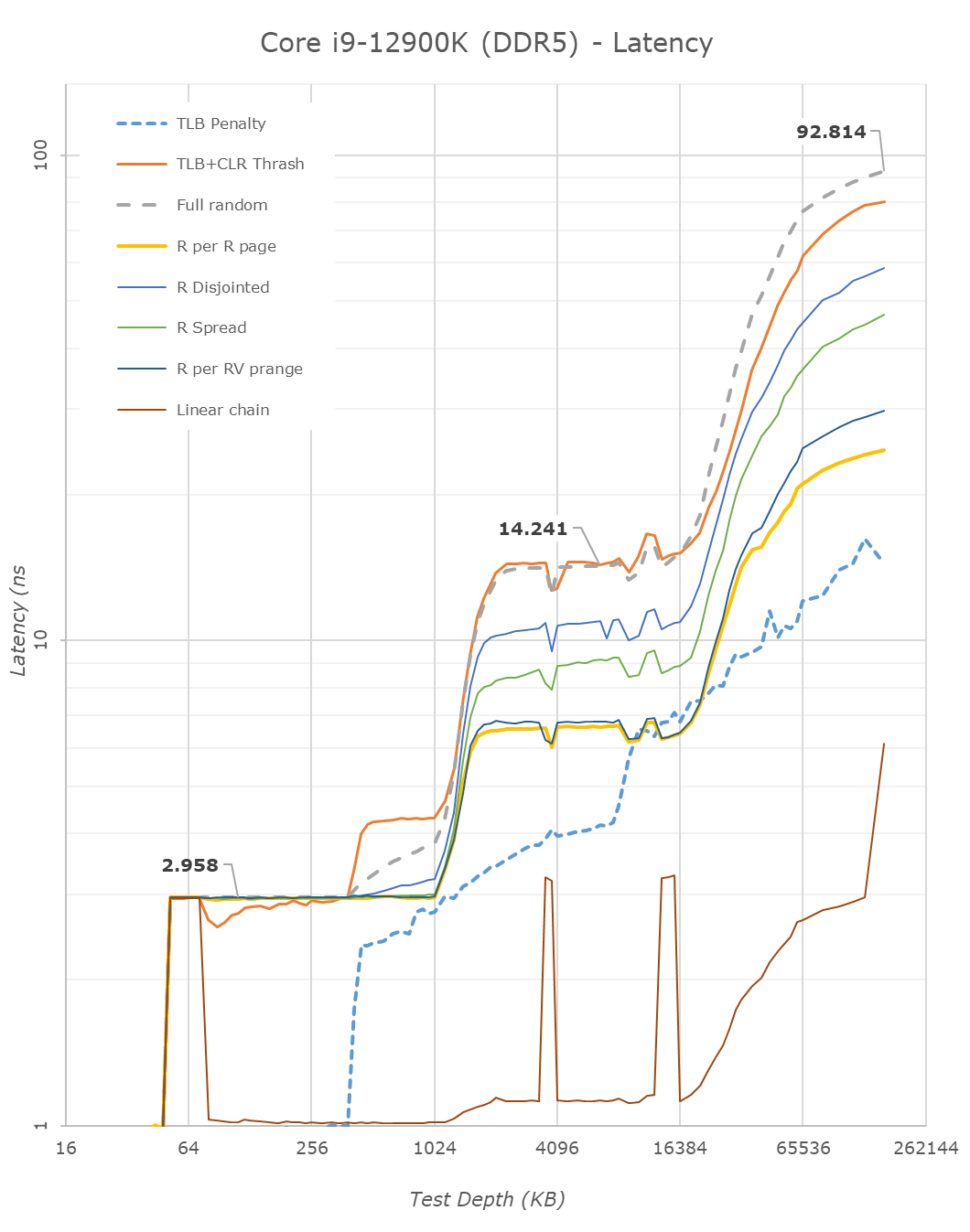
Luckily, Anandtech tested this on the M1 Max, which seems like it was equipped with similar or the same memory the new models have:
So far, I see no evidence that putting LPDDR5 in-package reduced latency.
You can also just do the math. Using a conservative estimate, signals should propagate at least 150 mm per ns. So, maybe putting it in-package shortens the round-trip path by a couple nanoseconds? Clearly, not enough to justify it on the basis of latency.
As far as YOU can tell? And yet you complain that other people are "just making things up"!!!
I was referring to the fact that I'm just guessing about the memory inside the M2 Pro and Max, because I have yet to see the actual specs. Therefore, I was attempting to extrapolate from the M1 Pro and Max.
Have you read my technical discussions of M1, including details of how M1 memory system works? Uhh...
There is a LOT more going on there than you can possibly imagine, starting with characterization of each DIMM in the factory, which is then burned into a ROM on the SoC and used to optimize the voltage and refresh rates applied to each DIMM.
The issue is not that the DIMMs are run at a higher frequency when on the package, it is that they
- use less energy (lower wire capacitance) -- this is obvious
- they can be characterized and that characterization aggressively exploited (this is much less obvious)
So, how much power do they save and how much higher speeds can they reach? That all seems like tweaking around the margins. Not to trivialize it, because I know that lots of little gains can stack up, but still... not on the scale of some of the hyperbole.
My point was that nothing magical happened by putting the memory in-package. The speed & latency are still pretty much what you can get with external memory. The huge jumps in speed (i.e. reaching 200 or 400 GB/s) instead comes from widening the data bus. Something that might be less practical to do in a laptop with external DRAM, but not outright impossible.
It also helps that Apple appears to have vastly superior memory controllers to Intel. I've no idea why, but the bandwidth differences between Apple and Intel are stunning. Intel get slightly lower latency at the cost of vastly lower bandwidth, and overall it seems like they're making sub-optimal tradeoffs.
Could it be something as basic as Apple optimizing around ARM's memory model?
Are the main performance differences on write & copy, with similar performance for reads? In that case, I'd suggest that Intel isn't predicting cacheline overwrites, and therefore suffering from the write-miss penalty.
So far, I see no evidence that putting LPDDR5 in-package reduced latency.
You can also just do the math. Using a conservative estimate, signals should propagate at least 150 mm per ns. So, maybe putting it in-package shortens the round-trip path by a couple nanoseconds? Clearly, not enough to justify it on the basis of latency.
(a) The AnandTech graphs are occasionally problematic. The BIG problem is that some of the tests are scaled by page size so that the tests for various types of prefetching are misleading (ie the Apple test is doing a test of how a certain type of pattern spread over N*16KB is prefetched, while the Intel [or other ARM] test is doing a test of how a certain type of pattern spread over N*4KB is prefetched). It's an easy mistake to make when you start off in a world of everyone has 4K pages, then never think about it!
When I ran similar tests I found that in a few cases Apple did rather better than expected because of this effect.
(b) No-one (reliable!) is claiming that Apple has lower "full-random" latency than Intel; that's not true and it's obviously not true. Neither is anyone claiming that how DRAM chips are mounted is an important factor in latency.
As far as on-chip packaging is concerned, the point is, as I said power. This is the HUGE factor, the one Apple cares about most.
(c) Apple makes a different set of tradeoffs in its memory controller (broadly considered, this includes the NoC and the SLC) than Intel. These begin by being vastly more biased towards saving power; secondarily they are based on spending area whereas Intel spends frequency. Yes Intel gets lower latency for full-random access; but for most use cases this doesn't translate into better performance compared to Apple's tradeoffs, which are biased towards much smarter prefetching and decisions as to how data is move between and retained in caches.
Secondarily (again this costs a little latency but seems to be a good tradeoff) Apple takes QoS REALLY seriously across every aspect of the chip. This gives vastly improved "responsivity" (things like video never glitching no matter what else is going on). At some point, when people starting using VMs seriously on Macs, I suspect this will also pay off in things like much less ability for one VM to hurt the performance of another VM, something people seem to care about a lot in the cloud space. But I have seen zero serious investigation of VM behaviors on Apple Silicon, so this is just a guess. (Another guess, based on the patent record, is that VM behavior on M2 is rather better than on M1, more so than you'd guess from just the specs. Hopefully SOMEONE will eventually start benchmarking this sort of stuff.)
This can't be true. Not if you're using the exact same compiler & version, targeting the same ISA, and using the same options.
Michael has run various benchmarks on the M1, over the past couple years -- both running Linux and MacOS -- and we've never seen anything remotely close to what you claim.
Yeah, this seems crazy, unless the AMD machine is horribly misconfigured (using HD not SSD? too little memory so there is massive swapping?)
A more realistic apple's to apple's comparison is about 2x for an Apple Silicon M1 machine compared to the most recent equivalent Intel machine, eg
 Tweet
Tweet

Comment