
 Tweet
Tweet
Kernel 5.3 requires 6.0.14+ or 6.1 beta.
-
-
Correct me if i am am wrong, but weren't they advertising for graphics development help, specifically around Vulkan and DX? I think they want to improve GPU acceleration but they need someone with the expertise to contribute.
Seems like all of the open source GPU developers have either burn out or are taken advantage of consistently and move on.
Comment
-
This is misleading. The SGI Altix or its newer offspring UV3000 servers with 1000s of cores which the picture make a reference to, is a HPC cluster, doing scientific calculations. These clusters cannot run normal business workloads.Originally posted by Calinou View Post
There are basically two types of large servers: scale out or scale up.
-Scale out servers are clusters. They run 1000s of cores (or cpus as some prefer to say) with 10s of TB ram, all solving a mathematical equation on a grid, running the same equation over and over again. Here we have SGI Altix/UV3000/ScaleMP/etc clusters.
When you have this many cpus, it is impossible to connect each cpu to another - there would be too many connections. For 256 cpus, there would be C(256, 2) connections:
which amounts to 32640 connections. Each cpu needs to be connected to each other, etc. And this results in 32000 connections. This is impossible to build, already with as little as 256 cpus. Therefore, you group cpus into clusters. And each cluster is connected to another cluster, this keeps the number of connections down. So if cpu no 1 needs to talk to cpu no 255, then there will be several hops. The signal needs to hop from cluster to cluster to finally the cpu. This means there will be lot of hops. And this kills performance when you have workloads that need to talk to each other, such as business workloads, typically large database, or ERP enterprise software or SAP.
The thing is business software servers typically serve thousands of users simultaneously, one user doing accounting, another doing database, etc. So the source code will branch heavily, because all users do different things at the same time. All these different user's data cannot be cached into cpu cache. This means the cpus needs to go out to RAM all the time. RAM is typically 100ns, which is the equivalent of a 10 MHz cpu. This is sloooow. And if you also use lot of cpus, you need to hop from cluster to cluster to find the correct cpu. So you will need say, five hops. Each hop adding 100ns, so you look at 500ns. Which is the equivalent of a 2 MHz cpu.
So, the more cpus you add, the more connections you need. At some point the number of connections between cpus will be too large, so you can only run embarassingly parallell workloads on these large clusters, i.e. each cpu runs the same piece of code, but on a small local grid. This code can fit into the cpu cache. So clusters can only run HPC scientific computing because these types of workloads do not need to talk to each other. Synchronization betweeen cpus and communication between cpus, kills performance.
So large clusters can only run calculations. Serving a single scientist, starting up a batch job running for weeks. Like supercomputers - which are all clusters.
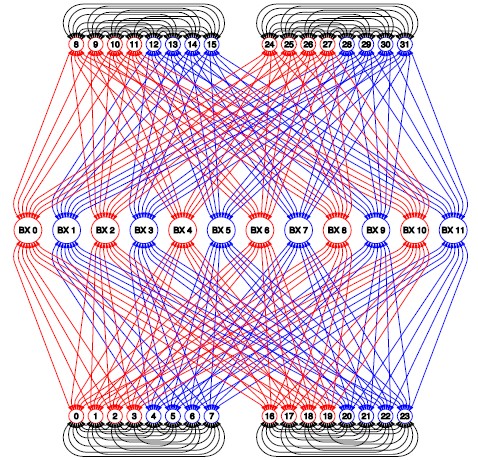
OTOH, business servers serves 1000s of users, so there will be lot of communication between the cpus. Therefore business servers typically max out at 16 cpus, or even 32 cpus. This allows each cpu to connect to each other, reducing the number of hops. Thus you need to look at the topology of the server; is every cpu connected to each other? Or are the cpus so many they need to be grouped into big clusters - and then each cluster are connected to another cluster which keeps the number of connections down. Here we have a typical 16 cpu business server. We see that when the red cpus communicate, there are 3 hops, i.e. 300ns. This is a Linux x86 server. The topology is very bad, performance crawls because there is 3 hops in worst case when cpus are far away.

Imagine a 256 cpu server, where the cpus communicate much. There will be lot of hops maybe 1.000ns of latency, which corresponds to a 1MH cpu, performance will get killed. Therefore, large servers never run business software, they only run HPC scientific calculations. BTW, (SAP HANA is a clustered workload).
If we instead look at a Unix scale-up server, the SPARC M5 server. It has 32 cpus. Look at the topology. Maximum 2 hops to reach any other cpu. This scale-up business server is much faster.
So, in short, large business servers max out at 16 or even 32 cpus. And they are all exclusively Unix/RISC or Mainframes, no x86 servers existed in this business server domain. Last year(?) we saw the first Linux 32 cpu server. It was first generation and therefore had bad topology with many hops, and thus performance was way behind Unix/RISC.
So whenever you see large cpus with 1000s of cores/cpus, remember they are clusters running calculations for weeks. The largest business servers max out at 32 cpus. Actually, Fujitsu sells the M10-4S SPARC server, it has 64 cpus. The fastest SAP benchmarks all belong to UNIX/RISC. x86 is way behind. There are no large SGI clusters running SAP benchmarks, because clusters cannot run SAP, because SAP is a business workload.Comment




Comment