
 Tweet
Tweet
Phoronix: Intel Talks Up 2024 Xeon Sierra Forest & Granite Rapids At HotChips
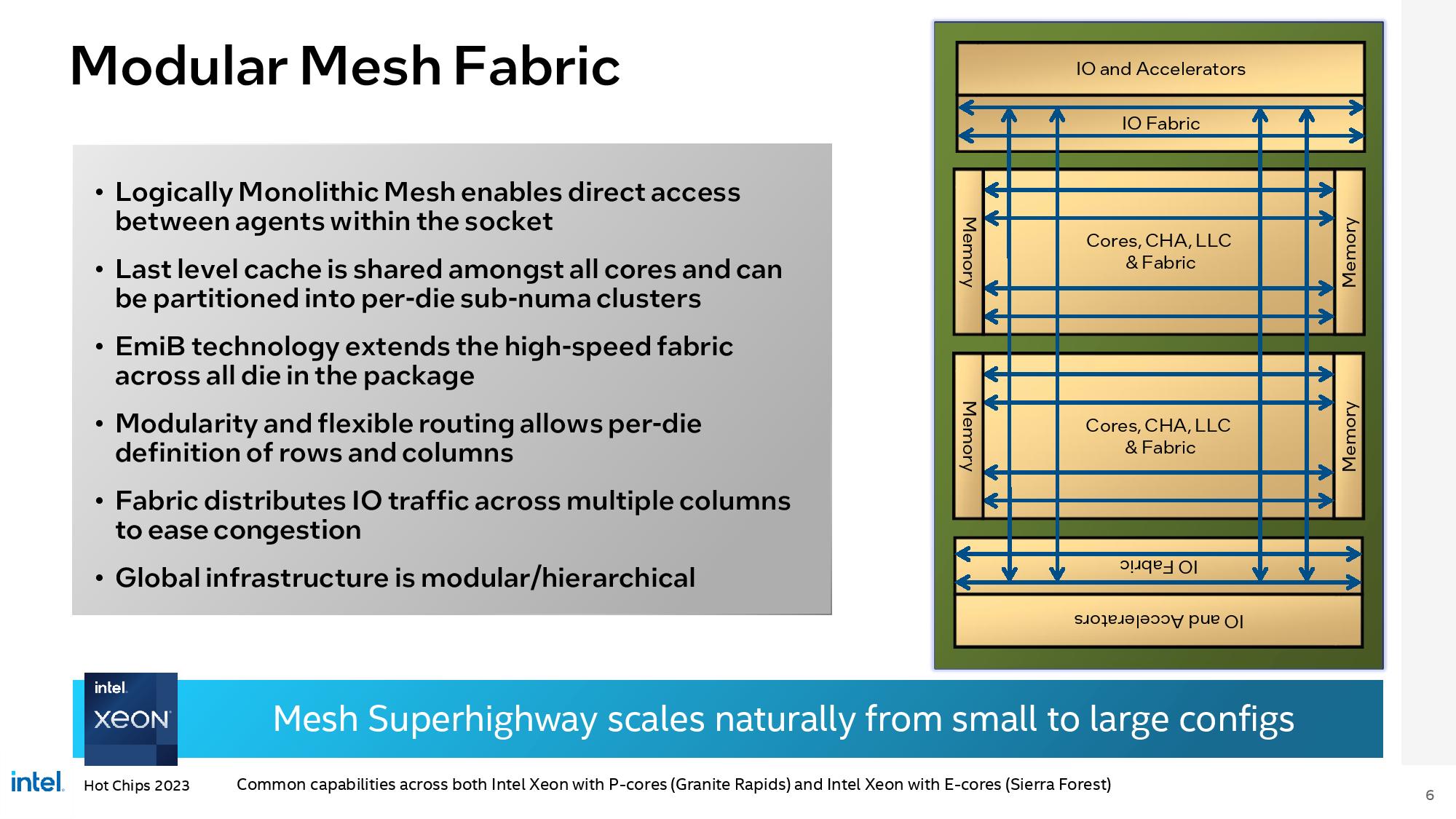
For HotChips 2023, Intel has made some new disclosures around Granite Rapids and Sierra Forest.
For HotChips 2023, Intel has made some new disclosures around Granite Rapids and Sierra Forest.


Comment