
 Tweet
Tweet
Phoronix: AMD CDX Bus Landing For Linux 6.4 To Interface Between APUs & FPGAs
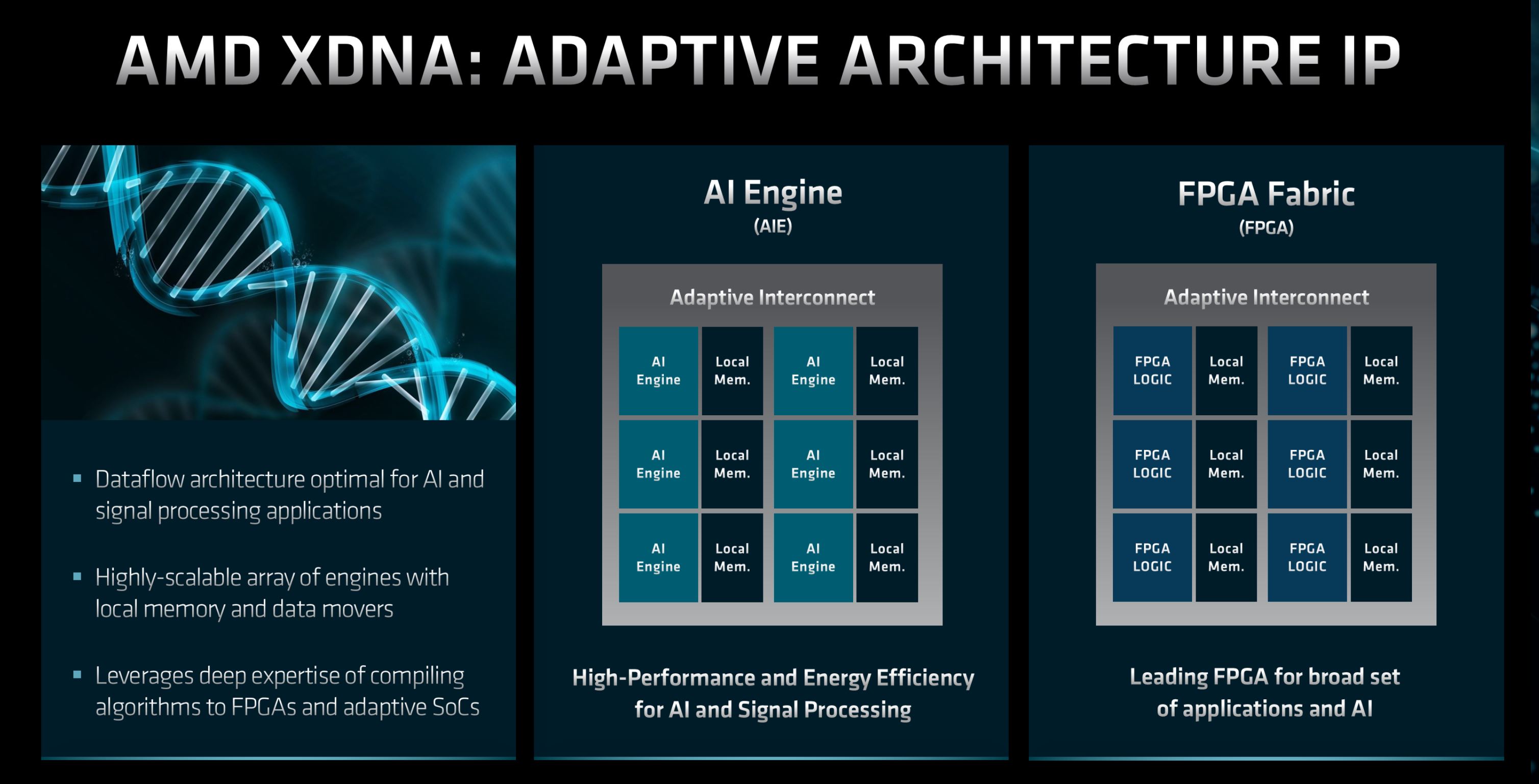
Since last year AMD-Xilinx has been posting Linux patches for enabling CDX as a new bus between application processors (APUs) and FPGAs. The AMD CDX bus is now poised for introduction in the upcoming Linux 6.4 cycle...
Since last year AMD-Xilinx has been posting Linux patches for enabling CDX as a new bus between application processors (APUs) and FPGAs. The AMD CDX bus is now poised for introduction in the upcoming Linux 6.4 cycle...


Comment