
 Tweet
Tweet
Sorry, with all so respect, I do not believe these results, until I see your independent benchmarks.
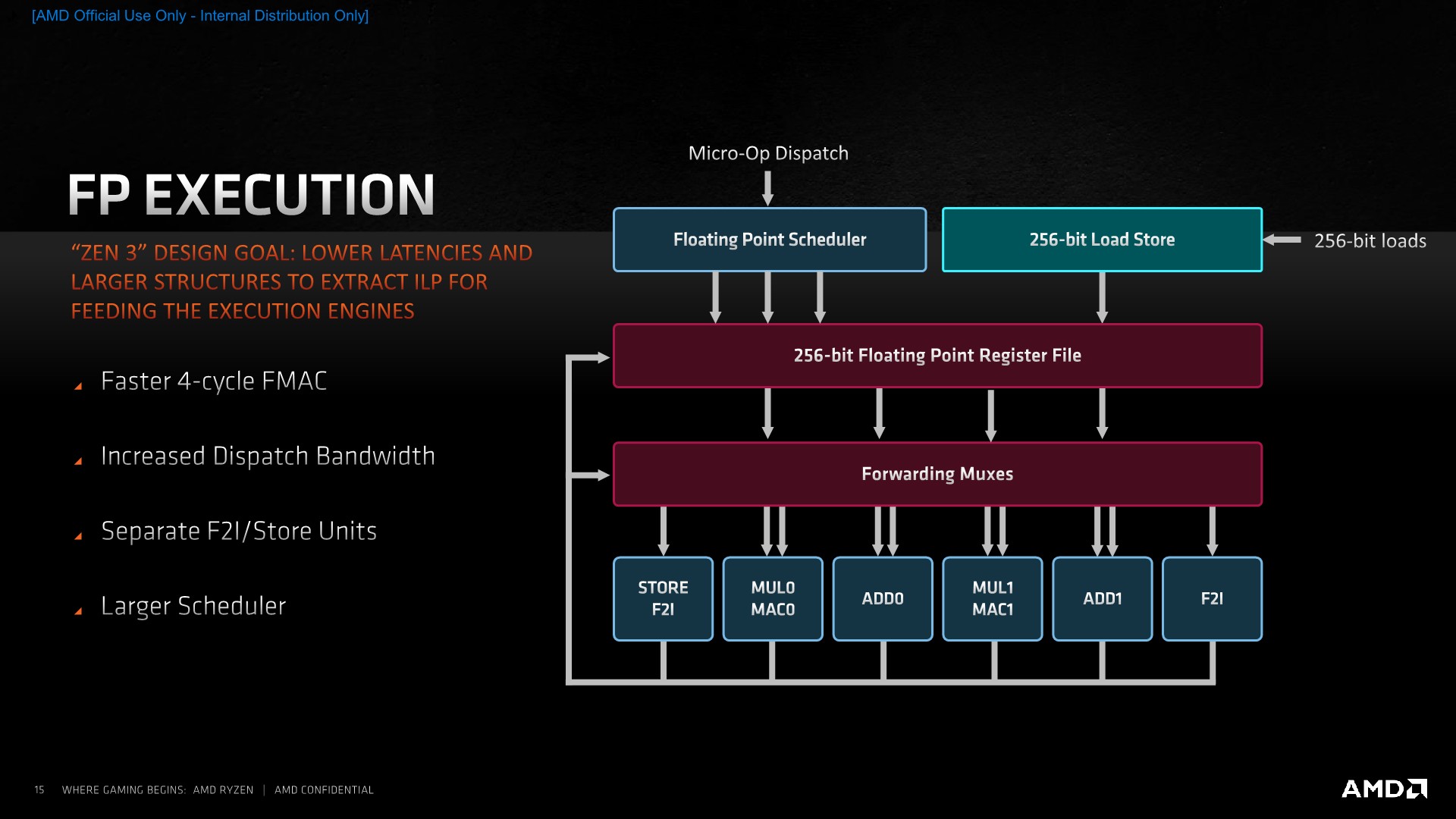
AMD Epyc zen 3 has two avx2 (somewhat avx256) per core, for those who did not know.
Xeon platinum has two avx512 per core. Other Xeon processors have one avx512 per core.
Should we compile NumPy to enjoy these optimizations or the version in anaconda is already enables avx?
AMD Epyc zen 3 has two avx2 (somewhat avx256) per core, for those who did not know.
Xeon platinum has two avx512 per core. Other Xeon processors have one avx512 per core.
Should we compile NumPy to enjoy these optimizations or the version in anaconda is already enables avx?




Comment