
 Tweet
Tweet
And what AMD pioneered and abandoned with HSA, Apple is now the leader.
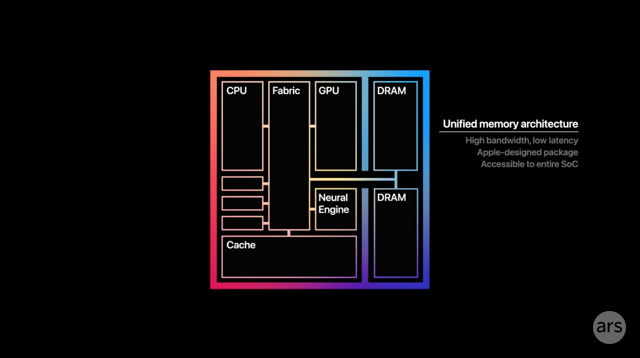
Unified memory architecture
UMA stands for "unified memory architecture." When potential users look at M1 benchmarks and wonder how it's possible that a mobile-derived, relatively low-power chip is capable of that kind of performance, Apple points to UMA as a key ingredient for that success.
Federighi claimed that "modern computational or graphics rendering pipelines" have evolved, and they've become a "hybrid" of GPU compute, GPU rendering, image signal processing, and more.
UMA essentially means that all the components—a central processor (CPU), a graphics processor (GPU), a neural processor (NPU), an image signal processor (ISP), and so on—share one pool of very fast memory, positioned very close to all of them. This is counter to a common desktop paradigm, of say, dedicating one pool of memory to the CPU and another to the GPU on the other side of the board.
When users run demanding, multifaceted applications, the traditional pipelines may end up losing a lot of time and efficiency moving or copying data around so it can be accessed by all those different processors. Federighi suggested Apple's success with the M1 is partially due to rejecting this inefficient paradigm at both the hardware and software level:
That's not the only optimization. For a few years now, Apple's Metal graphics API has employed "tile-based deferred rendering," which the M1's GPU is designed to take full advantage of. Federighi explained:
Unified memory architecture
UMA stands for "unified memory architecture." When potential users look at M1 benchmarks and wonder how it's possible that a mobile-derived, relatively low-power chip is capable of that kind of performance, Apple points to UMA as a key ingredient for that success.
Federighi claimed that "modern computational or graphics rendering pipelines" have evolved, and they've become a "hybrid" of GPU compute, GPU rendering, image signal processing, and more.
UMA essentially means that all the components—a central processor (CPU), a graphics processor (GPU), a neural processor (NPU), an image signal processor (ISP), and so on—share one pool of very fast memory, positioned very close to all of them. This is counter to a common desktop paradigm, of say, dedicating one pool of memory to the CPU and another to the GPU on the other side of the board.
When users run demanding, multifaceted applications, the traditional pipelines may end up losing a lot of time and efficiency moving or copying data around so it can be accessed by all those different processors. Federighi suggested Apple's success with the M1 is partially due to rejecting this inefficient paradigm at both the hardware and software level:
We not only got the great advantage of just the raw performance of our GPU, but just as important was the fact that with the unified memory architecture, we weren't moving data constantly back and forth and changing formats that slowed it down. And we got a huge increase in performance.
And so I think workloads in the past where it's like, come up with the triangles you want to draw, ship them off to the discrete GPU and let it do its thing and never look back—that’s not what a modern computer rendering pipeline looks like today. These things are moving back and forth between many different execution units to accomplish these effects.
And so I think workloads in the past where it's like, come up with the triangles you want to draw, ship them off to the discrete GPU and let it do its thing and never look back—that’s not what a modern computer rendering pipeline looks like today. These things are moving back and forth between many different execution units to accomplish these effects.
That's not the only optimization. For a few years now, Apple's Metal graphics API has employed "tile-based deferred rendering," which the M1's GPU is designed to take full advantage of. Federighi explained:
Where old-school GPUs would basically operate on the entire frame at once, we operate on tiles that we can move into extremely fast on-chip memory, and then perform a huge sequence of operations with all the different execution units on that tile. It's incredibly bandwidth-efficient in a way that these discrete GPUs are not. And then you just combine that with the massive width of our pipeline to RAM and the other efficiencies of the chip, and it’s a better architecture.
https://arstechnica.com/gadgets/2020...on-revolution/
https://arstechnica.com/gadgets/2020...on-revolution/

Comment