
Originally posted by jayN
View Post
Originally posted by jayN
View Post
Originally posted by jayN
View Post
Don't get me wrong: for the enthusiast, that would be bad. I have a Radeon VII at home and a Titan V at work. I love that these are all-purpose accelerators, from fp64 to AI and graphics. And it was AI that motivated the purchase of the Titan V, so we also got an awesome graphics card as a bonus. I'm just saying that it seems time for Nvidia to finally do a more targeted AI training processor, to continue to remain competitive in that market.
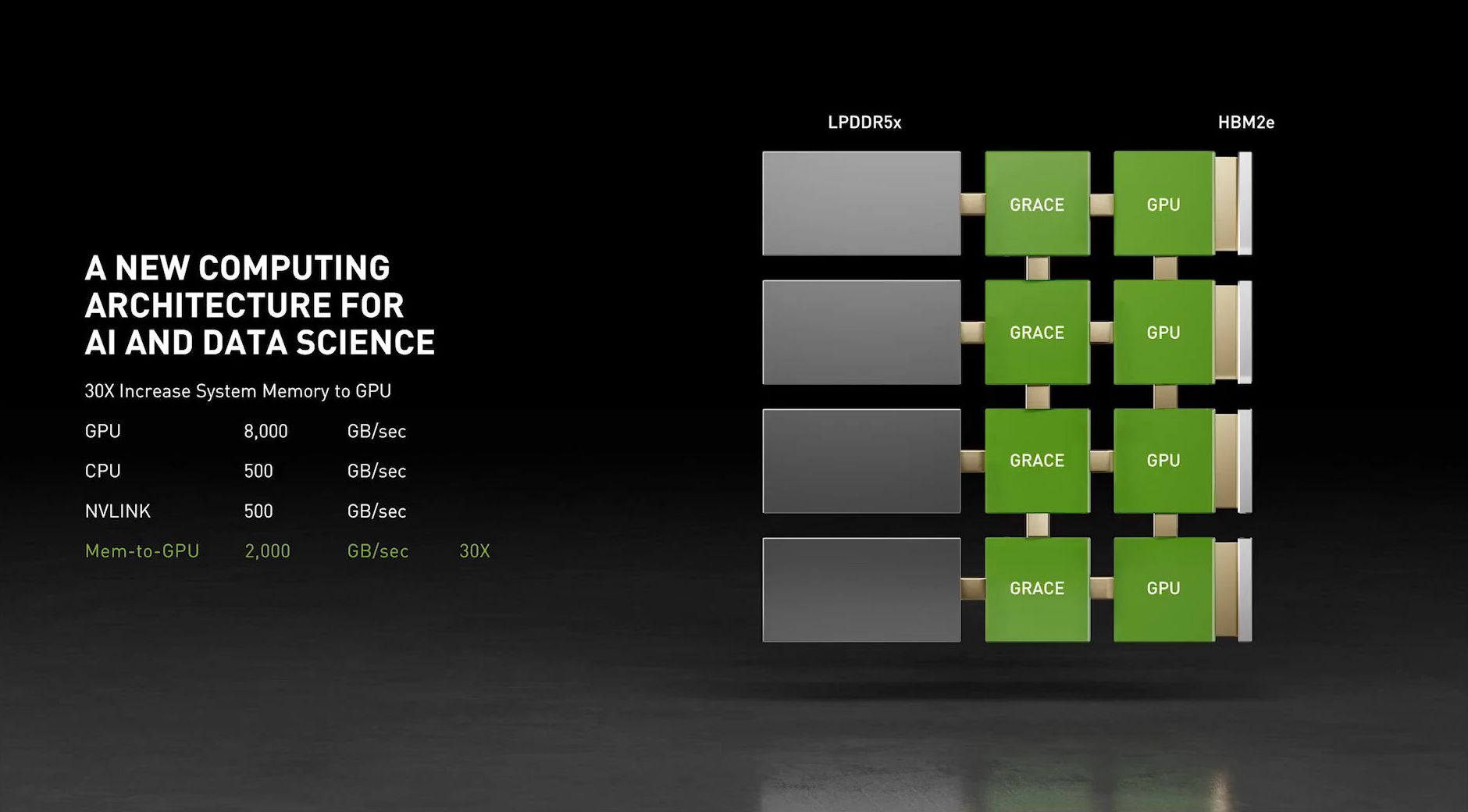
Leave a comment: