
GCC & LLVM Clang Performance On The Intel Atom

Compared to our earlier GCC and LLVM benchmarks across three systems, the testing under the Intel Atom netbook was similar where the C-Ray ray-tracing benchmark performance improves measurably with each major GNU Compiler Collection release between GCC 4.3.5 and GCC 4.6.0. On the Intel Atom N270, the C-Ray speed improves by 17% between GCC 4.3.5 and GCC 4.6.0-20101120. Clang with LLVM 2.8 meanwhile ran just slightly faster of GCC 4.4.5.

With the Hiemno Poisson Pressure Solver in our earlier GCC/Clang benchmarks the performance was relatively unchanged on both Intel systems (based on the Core 2 Duo and Core i7 Gulftown CPUs) while the AMD Opteron 2384 performance improved significantly when leveraging LLVM compared to the vanilla GCC, even when it came to using DragonEgg and LLVM-GCC. With the Intel Atom we see a similar boost when using LLVM on Himeno, However, here the speed-up is even more sizable! It was about a 40% jump in performance when building Himeno with Clang 2.8 rather than GCC 4.6, but with the 32-bit Atom CPU when switching to Clang the output performance more than doubled. The GCC-built Himeno was handling around 13 MFLOPS where the LLVM+Clang-built version topped 30 MFLOPS.

With the MAFFT Multiple Sequence Alignment test, the Clang-built binary was marginally slower than the GCC 4.6 development snapshot.
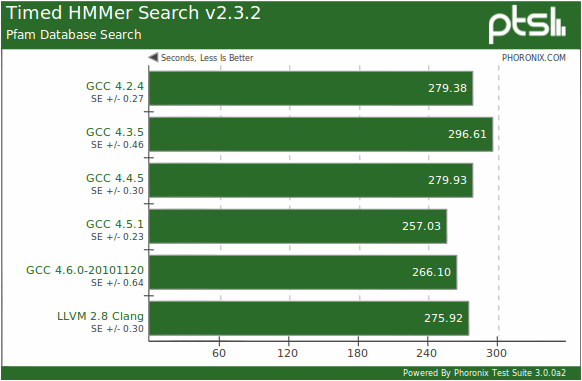
With HMMer in our earlier open-source compiler tests, we found the LLVM-based solutions (Clang, DragonEgg, and LLVM-GCC) to run significantly slower than pure GCC on all three Intel/AMD systems. With the Intel Atom netbook running this scientific test, however, LLVM's Clang was only slightly slower. The compiler producing the fastest binary was GCC 4.5.1.