
 Tweet
Tweet
Originally posted by duby229
View Post

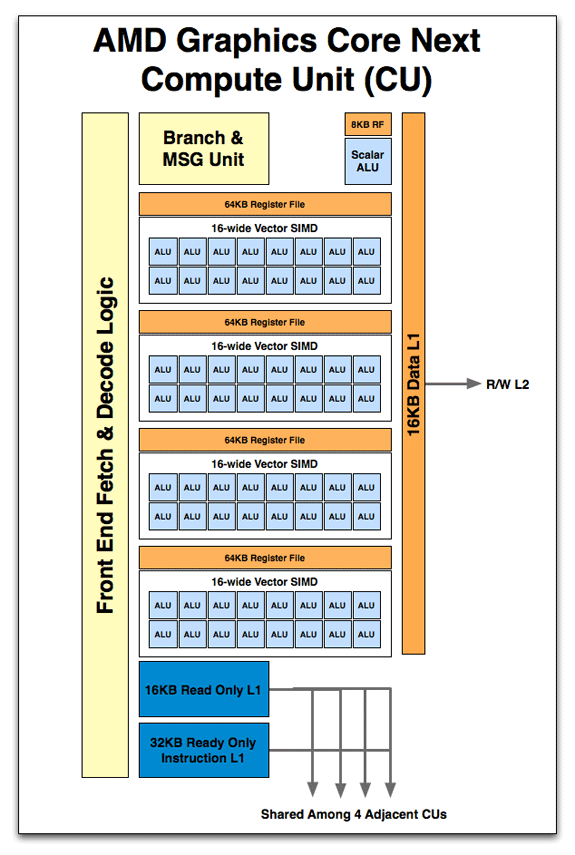
Search for "in-order", "To preserve in-order execution, each instruction must also come from a different wavefront;" in CU FRONT-END section. This is about instruction execution.
Search for "out-of-order", "Tasks complete out-of-order, which releases resources earlier, but they must be tracked in the ACE for correctness." in SYSTEM ARCHITECTURE. This is about Asynchronous Compute.
I don't think there are any throughput optimized architecture that executes instructions out-of-order. In fact, the whole point of building throughput optimized architecture is to use more transistors for calculation instead of instruction execution order tracking.



Comment