
 Tweet
Tweet
Originally posted by coder
View Post
-
Wow, now this is impressive. Thank you, I'll have to look deeper into it. -
Isn't that the whole point of VLIW?Originally posted by coder View Post
And not to get to distracted here, the evolution of my thought process here went from "surprised Elbrus havent done something similar to the new M1" to "hmmm these are quite similar" while some random other was insisting "long instruction words that contain multiple RISC instructions that run in parallel" is a terrible design that will never compete with x86.
Comment
-
There IS an order, namely the order that the instructions are laid out in memory that the CPU reads (the technical term being "program order"). The whole premise of OoO is that the CPU can look at a big window of instructions and execute them in any order it likes (including in parallel) as long as it stores the result of these finished instructions in a hidden buffer (the ROB mentioned by coder a few messages upwards in this thread) and commits the results in the original program order.Originally posted by mSparks View Post
In contrast, with VLIW the idea is to encode opportunities for parallelism directly in the ISA allowing the CPU to dispense with all this OoO machinery.
Well, VLIW is a technical term with a reasonably well defined meaning, whereas "ultra wide execution architecture" is just marketing gibberish.They call it "Ultra wide instruction arch". Doesn't mention that either.
Comment
-
Either they run in a sequence and therefore have an order,Originally posted by jabl View Post
Or
They run in parallel and therefore have no order.
Reasonably sure there is no middle ground there.
Comment
-
No, a reorder buffer is for on-the-fly scheduling of instructions to execution units. That runs counter to VLIW. Classical VLIW is where all scheduling of instructions to execution units happens at compile time. And that means whenever there's a stall, it affects all execution pipelines, because they all run in lock-step.Originally posted by mSparks View Post
It's a bit hard to explain with words, but try to think of a VLIW instruction stream in terms of a 2D grid. The Y-axis would be time (i.e. instruction cycle), while the X-axis would be "slots". Each slot has certain restrictions on it, such as which types of execution units it can target.
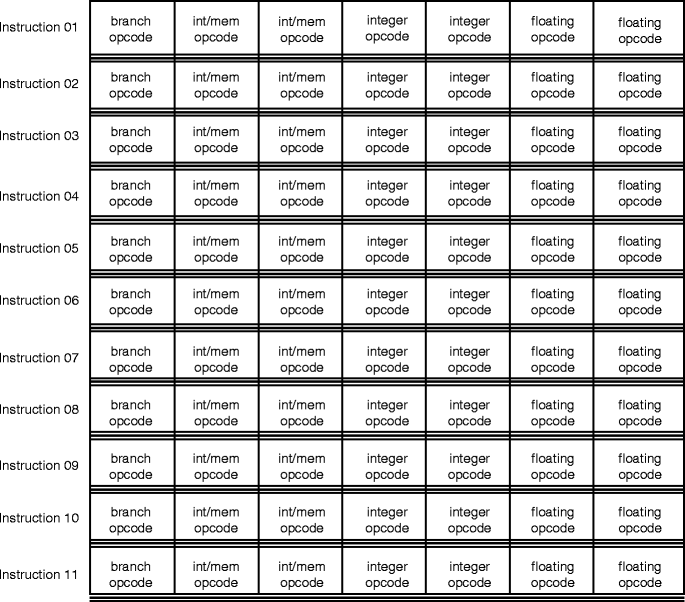
Anyway, that's the basic idea. There's been lots written about it. VLIW is a basic category of CPU ISA that's been around for at least 40 years.
You can find several modern examples of it, here:
BTW, something else mentioned in this thread is EPIC, which is a term Intel introduced with IA64 and the Itanium. It's a hybrid between VLIW and RISC. @tux3v has suggested (some) ELBRUS processors might be EPIC, rather than VLIW.
Last edited by coder; 24 February 2022, 10:34 PM.Comment
-
Do soldiers marching in formation have an order? I'd say they do. They don't have a linear sequence, but they have an order you can express in 2 dimensions.Originally posted by mSparks View PostComment
-
Not without a general to put them in order.Originally posted by coder View Post
"Out of Order" literally means running them in parallel on the same clock cycles -> the ordering was removed - they were taken "out of order" because the ordering wasn't important, and there was spare execution units available to run them in parallel (and if there wasn't taking them out of order would have no benefit).
afaict VLIW makes it explicit and bundles instructions together where the order/sequence they are executed in is not important - in your diagram, all the opcodes in each instruction are run "out of order" , for example there is no left to right ordering - or no?Last edited by mSparks; 24 February 2022, 10:39 PM.Comment
-
Okay, in a Out-of-Order CPU, we call that General the Scheduler. He is continually monitoring the marching and when one column gets held up, he rearranges the soldiers (but still ordering by rank), to keep the parade moving at a good rate. He has a notebook, which he uses to track which soldiers go where, and that's called the Reorder Buffer.Originally posted by mSparks View Post
In a VLIW compiler, the General is called the compiler. He tells the soldiers where to go, in advance. He knows enough about each soldier to guess which ones might get held up by certain obstacles, and arranges them accordingly.
Not a perfect analogy, but I tried.
: )
I think the best way to understand out-of-order is to think about the simple case of a CPU that can only dispatch a single instruction in any clock cycle. Now, let's say one instruction is to read something from memory, which takes a while. Out-of-Order execution just means the CPU can dispatch other instructions while it's waiting on the data to come in from memory.Originally posted by mSparks View Post
If the CPU were in-order, then whatever comes after that memory read instruction would have to wait until the read completes, even if the next instruction didn't use the result of the read.
Once you understand how a CPU can reorder instructions serially, then it's a simple step to see how the same principles apply for dynamically assigning them to run in parallel multiple execution units.
Order is important, for certain instructions. Think of it like a directed acyclic graph or a dataflow diagram. This shows which instructions depend on the results of other instructions. Typically, instructions have only one or two inputs, which means one or two direct dependencies, each.Originally posted by mSparks View Post

As long as the compiler doesn't break these dependencies, it can schedule the instructions into slots of those instruction words. This is the same thing an out-of-order CPU is trying to do, on-the-fly.
I'm not sure how clear that is. I'm no professor. Again, you can find a lot written about these subjects, if you're interested.Last edited by coder; 24 February 2022, 11:58 PM.Comment
-
Yes, I confirm. I just wanted to mention that this will be time when quantity becomes quality. Take a look to perfect VLIW with memory without latency. To make it efficient you need N independed "subtasks" where N is VLIW width. With imperfect case, when you need to hide memory latencies, for example 10 cycles (typical L2), you need N*10 instructions which aren't depend on data from memory. In case of L3 there must be N*40.Originally posted by coder View Post
In same scenario OoO will stall each "subtask" individually and for minimum required time each.
Not sure. When you need big caches you'll have to waste much more energy.This is not true. VLIW has better power-efficiency, if you can keep it from stalling. That's by avoiding scheduler overhead.
SIMD will show same performance and some FPGA or ASIC units will crush VLIW. Or, if you like exotic solutions, Cell-like CPUs can beat VLIW.So, for signal-processing applications that tend to have regular data access patterns,
Yes, R600 was based on VLIW. With SMT you can hide latencies and GPU tasks tend to vector math so it is easy to fill wide word with independent instructions. Still VLIW lost to scalar G80 at the time, and next AMD GPU architecture wasn't based on VLIW.it can be a significant win. There are lots of DSPs and AI chips that use VLIW. Older GPUs also did so, until they figured out that wide SIMD + SMT was a better solution (but still in-order!).
VLIW can't compete with OoO in general use single threaded performance, it can't compete with scalar SIMD with GPU-like tasks. There are no niche for them. There are at least same efficiency alternative solution for every task VLIW tried to solve.
I can trust Intel with this. They admitted EPIC have no value.Also, you're limited in your thinking. You only talk about classical VLIW, not EPIC. EPIC saves less runtime overhead than VLIW, but still allows for things like OoO and speculative execution. Compared with classical OoO, you save on having to detect data dependencies.
Comment
-
That is true only for strong memory order CPUs.Originally posted by jabl View Post
For weak order they just have to ensure this write op performs after it was confirmed (speculative execution marks some ops like 'not sure it should be executed'). With different cache strings week ordered CPU (arm for example) can write second data to it's L1 cache while waiting for previous write cache synchronisation.
Comment
Comment