
 Tweet
Tweet
Michael AFAIK Firefox doesn’t run natively yet, in which case those tests should be labeled Rosetta as well.
-
-
Originally posted by Jumbotron View Post
The translated x86 to ARM programs are significantly faster than I have expected, with many of them reaching around of 75% of the native speed, so a very good job done by Apple, but do not forget that the comparison is done with old x86 CPUs, and which were slower than their competition (due to anemic cooling) even at launch.
When compared to modern x86 CPUs, e.g. with Intel Tiger Lake or AMD Zen 3, the translated programs are much slower, so there is no surprise.
Of course, whoever was already happy with the old MacBook Air or Pro, will also be happy with the new ones, because in many cases the speed will be similar or even higher, even when running the old x86 programs.
Comment
-
I believe Firefox 83 is still x86_64 application. It works under Rosetta, but everything including Firefox, JS and JIT are x86_64 and emulated under Rosetta 2.
Try the Firefox Beta (84.0b3) or Firefox Nightly. They both come with both x86_64 and arm64 in single package for macOS. Be sure to run the same version on all machines, for consistency.
Also, I hope you do more native tests, with manually compiled binaries, not pre-built ones.
Also, thing will be interesting once Apple provides the virtualisation. They claimed to be able to run aarch64 Linux using Parallels on Apple Silicon. It is just not public yet. VMware is also working on virtualisation software for Apple Silicon. It also be interesting to try and compile qemu on macOS Apple Silicon. I know qemu does work on macOS on x86_64, but I have no idea if it uses any hardware virtualisation features for running x86_64 on x86_64, or fully falls back to TCG (software translator). However, even if it doesnt, it would be nice to run qemu-system-x86_64 on Apple Silicon arm64, just out of curiosity. It should boot Linux or FreeBSD without issues. Sure, I wonder how much slower it will be compared to Rosetta. (my guess ~2-3 times slower).
Another test I would like to see are performance differences between compiling clang targeting generic arm-8 , vs -march=native (or whatever is closest to the Apple Silicon).
Last edited by baryluk; 21 November 2020, 10:06 AM.Comment
-
I have already replied to another similar comment, but I want to stress this again, because I see too many such comments.Originally posted by blacknova View Post
There is nothing magic about Rosetta 2, even if it works better than many people, including myself, expected.
Rosetta + M1 does not work better than hardware x86 processors, it works better than *old* and *slow* x86 processors, as typical for Apple products in recent years, which is absolutely normal and to be expected.
The current x86 CPUs are Intel Tiger Lake and AMD Zen 3, both of which are much faster (e.g. +30%, +40% or more) than Rosetta 2 + M1, and that is also normal and to be expected.
It is speculated that Apple M1 might have a few extra instructions to simplify the x86-to-ARM code translation, for example for simulating the x86 handling of condition flags, but nobody knows for sure (except those who will not tell).
With such extra hardware helpers and because they have chosen to not translate AVX (whose registers would not fit inside the ARM registers), there should be many cases when the equivalent ARM code can reach close to 100% of the speed as the original x86 code, especially on a CPU with very large IPC like Apple M1, where it should be possible to execute in a single cycle the equivalent of a single x86 instruction, even when the translated ARM code would consist of several instructions, instead of only one.
So the fact that around 75% speed is reached by many programs is a great result for Apple, but it was far from an unreachable target.
Comment
-
That is a lot of talking. Show me data, graphs to back it up.Originally posted by AdrianBc View Post
Comment
-
That's still 4 times that of Zen and Skylake and 2.7 times Icelake. I-caches are 6 times larger than Zen and Skylake/Icelake. That is definitely crazy large. Plus L2 is 12MB for 4 cores, or 3MB per core, ie. 6 times larger than x86 cores. And finally there is 16MB L3, twice that of Renoir.Originally posted by evergreen View PostComment
-
He did, but burying your head in the sand is better I guess like an ignorant fanboy.Originally posted by baryluk View Post
You can look at benchmarks done between those old and slow x86 CPUs and current gen, and then extrapolate that on the graph. It ain't rocket science pal. Sorry to hurt your feelings.Comment
-
Maybe they bought that bidirectional cache patent from the Mill CPU guys.Originally posted by BillBroadley View PostComment
-
No way, IMHO he is right. If you take a look to anandtech benchmarks, emulated software runs roughly ~75% the performance of native via Rosetta 2 (source: https://www.anandtech.com/show/16252...le-m1-tested/6), considering there is a software emulation mechanism in the middle, this is just huge resultOriginally posted by Weasel View PostComment
-
Originally posted by Weasel View Post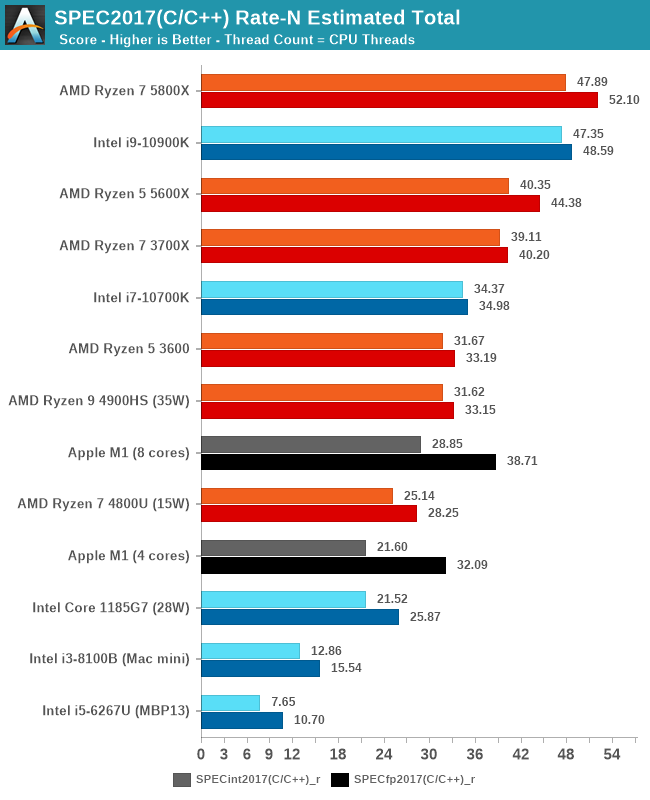
Weird, this appears to show a 20W M1 outperforming ryzen and tiger lake
Comment
Comment