
Originally posted by uid313
View Post
-
Well I guess one has to think that geekbench was mostlikly compiled with an apple compiler switching on all the nice flags making the dedicated package running like hell on this particular cpu. Or is it more an generic package for all arm cpus? Nonetheless nice performance. -
The blender benchmarks pick up improvement with reduced CCX with all cores. 5900X does not quite have the gains up to what you would expect compared to the 5600X.Originally posted by polarathene View Post
Its not just workloads jumping between cores its data sharing between threads that is required at times that hurts more when you have to cross CCX.
There was a prototype risc-v chip that showed 1024 cores to a single L3 and it worked fine. I do wonder if we will see like 12 and 16 core single CCX in future.
Leave a comment:
-
5600X and 5900X are hexa-core CCX, so the 5900X would have some overhead like latency when workload jumps between the two CCX, may not be as much of an issue depending on what you run, and if you keep it constrained to a specific CCX cores? But if you wanted to run something with 8/16 cores threads instead of 6/12, you'd have slight perf dip afaik.Originally posted by birdie View Post
For many it probably is negligible that it's not worth it, but I'd rather an full 8-core CCX personally. Those that don't care enjoy the savings of the models using 6-core CCXs.
---
Benchmarks generally are going to focus on single core/thread perf, or multi-thread(all the cores/threads), so this type of workload isn't going to look as advantageous in such a scenario obviously. Or do you know of a benchmark testing 8/16 core/thread workloads on a 5900X?Last edited by polarathene; 12 November 2020, 09:05 PM.Leave a comment:
-
Right, there can be a big latency between queueing and executing (waiting for dependencies) AND between executing and retiring (waiting for instructions from earlier in the program flow to get their dependencies and execute).Originally posted by duby229 View Post
If you think about a big queue where instructions are entered sequentially and retired sequentially, execute whenever their dependencies are satisfied, and stay in the queue after execution until all the instructions before them have retired that's pretty close. What makes it work is that instructions don't have to "work their way through the queue" unless there are earlier instructions waiting for cache or memory - it's more like a ring buffer than a physical FIFO.
If you really want a headache think about the fact that a lot of those already-finished instructions may have been speculatively executed and so the results need to be tossed if a branch goes in a different direction than what the predictor expected.Last edited by bridgman; 12 November 2020, 08:24 PM.Leave a comment:
-
To be clear, arm's Neoverse N1, IBM's Power9, and likely Apple's recent cores, break instructions into internal micro-operations during decode.Originally posted by duby229 View PostLeave a comment:
-
Yeah, I don't fully understand that. It is capable of queuing more instructions than it has the capability of issuing, which seems to me, would add latency between queuing and retiring. I don't know, maybe a longer pipeline hides it somehow.Originally posted by bridgman View PostLeave a comment:
-
Agree, but it is not specific to x86 since (a) micro-op caches already isolate the execution pipeline from decoder throughput in most cases and (b) building a wider decoder for a variable length ISA is not impossible, just another case of diminishing returns.Originally posted by duby229 View PostLeave a comment:
-
I agree with you. I just think we've already passed beyond the point of diminishing returns for x86. Anything further will be measured in tens of percents and not hundreds or thousands of percents. If we need to go wider, then more pipelines is the only feasible option. (And if you make each of those pipelines too big then -that- would produce diminishing returns on the number of pipelines possible)Originally posted by bridgman View PostLast edited by duby229; 12 November 2020, 06:09 PM.Leave a comment:

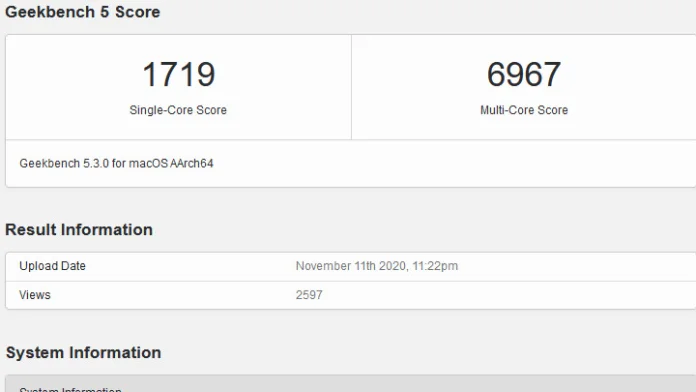
Leave a comment: