
 Tweet
Tweet
Originally posted by Syfer
View Post
-
Pi 3 and Pi 4 have the exact same instruction set. -
Does anyone have a 4 GB RPi on hand to test, I am curious if any of these tests are RAM limited? Also, I assume the Ondemand governor was used, although I don't think that will change anything significantly.Comment
-
Originally posted by ldesnogu View Post
Well that gap has narrowed considerably - it's now one generation as the upcoming Cortex-X1 pretty much matches A13 and the fastest Zen 2. Note the much higher power efficiency of the Cortex cores (showing that high performance does not mean inefficient):
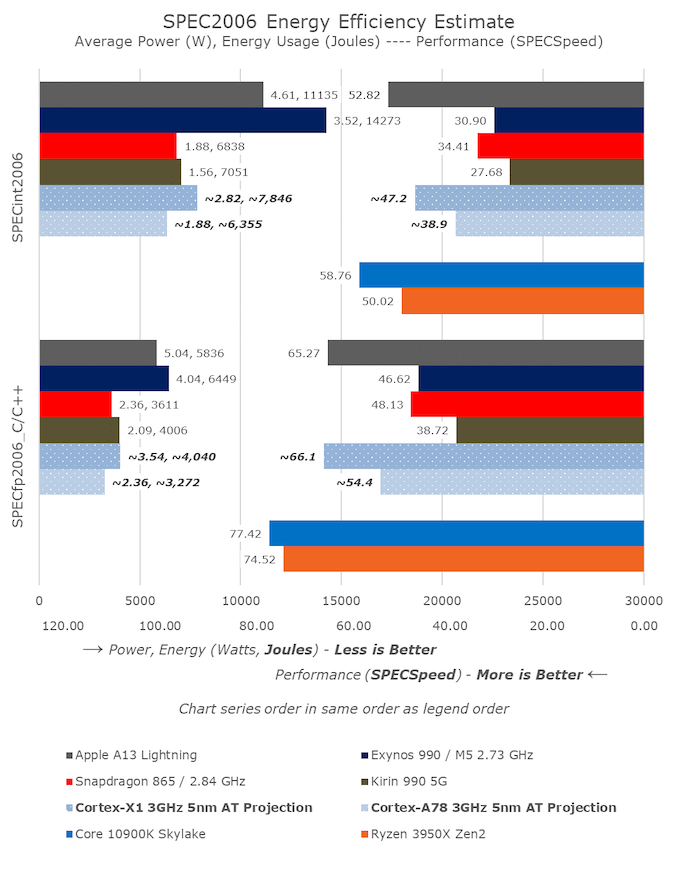
Comment
-
You can order high-end Arm servers and workstations online, eg. https://store.avantek.co.uk/arm-servers.html. Arm is expanding in servers, laptops and desktops, so there will be more choice in the future.Originally posted by JimmyZ View PostComment
-
I'm afraid that, in practice, the utilization of the load pipeline/path is way way lower than that (so you end up waiting). The utilization of the ALU pipelines is definitely better, but even there you rarely ever get close to 100% utilization.Originally posted by atomsymbol
I suggest the following experiment:
Start with a CPU intensive benchmark that lasts roughly 10-20 seconds (more is not a problem, it'll just make you wait a bit longer). The easiest thing is the compression of a larger file, which I also copied on /dev/shm. But feel free to pick your CPU intensive benchmark (this is not meaningful for an I/O benchmark that waits a lot ...)
Then run the following:
perf stat -e cycles,instructions,cache-references << your actual command >>
If your processor is an Intel one, the following should probably work as well:
perf stat -e cycles,uops_retired.all,mem_uops_retired.all_loads << your actual command >>
Generally, it's better to report uops vs instructions, and the uops_retired.all, mem_uops_retired.all_loads counters are precise on my processor.
Then see what the IPC is (instructions per cycle, or uops per cycle). Also see how frequent the loads are.
Please try the previous, as I'm curious what numbers you get. The first command should also work on an RPi2/3/4 actually.
Comment
-
ThanksOriginally posted by atomsymbol
It is indeed really difficult to do a negative proof in engineering - you can maybe show that something doesn't work in some circumstances, but the proof may be turned upside down when you change the setup.
Anyway, RENO does store-load bypassing in a way that I believe is worth doing. Also, see name of first author.
Comment
-
Except none of this has anything todo with loads reading the store output or the reverse.Originally posted by vladpetric View Post
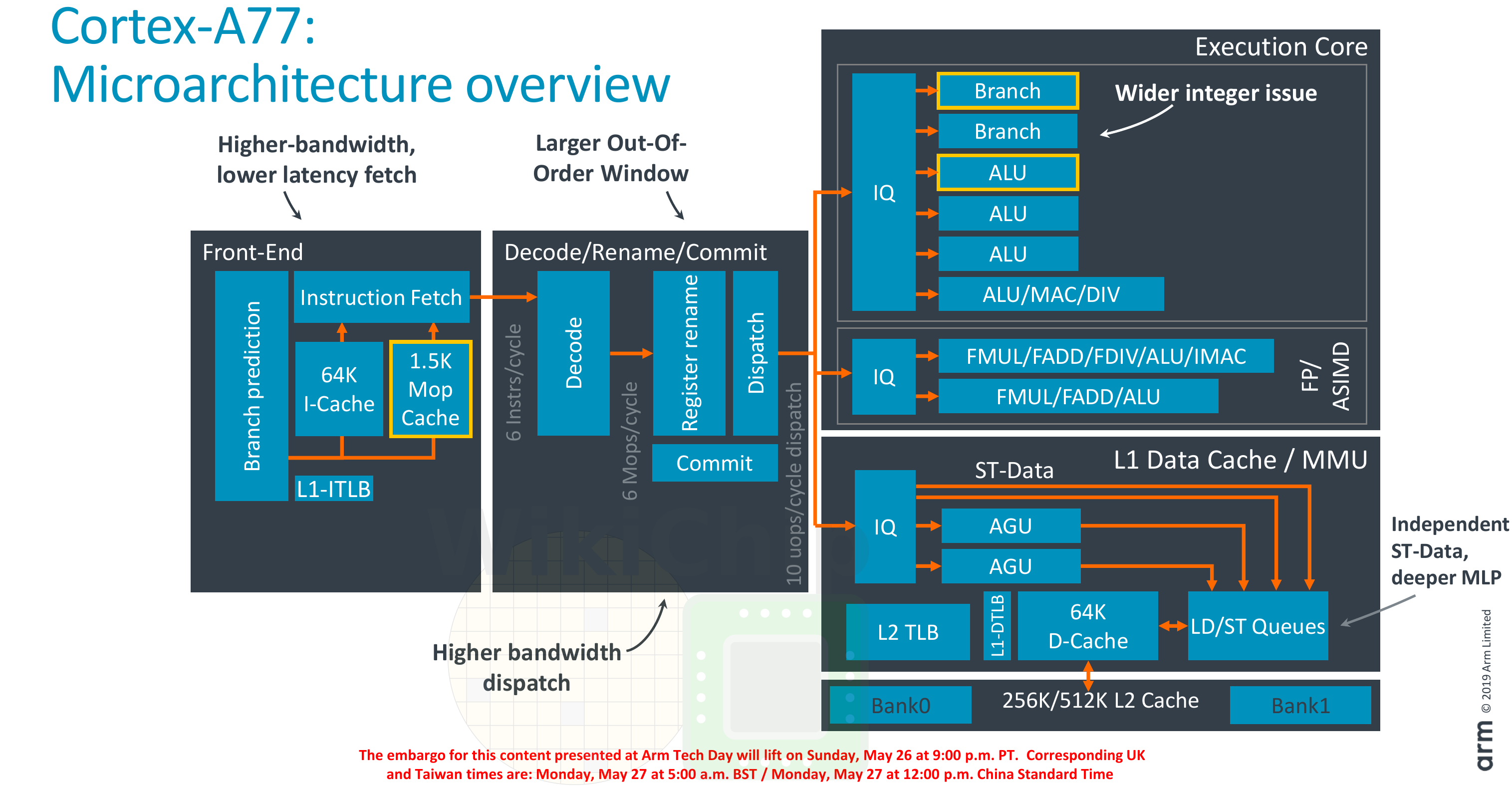
A77 increases IPC to double that of a A72 by in fact increasing the number of instructions decoded and being processed in the uops. Even that the A77 doubles the processed instructions per clock it only increases the uops by half.
A57, A72 and A76 in fact have the same number of micro ops. A57 is the RPI 3 that handles 2 full arm instructions per cycle. A72 that is RPI4 hands 3 full ARM instructions per cycle. A76 handles 4 instructions per cycle. So yes RPI4 A72 is not in fact filling the uops because it renaming enough instructions per cycle to use all the uops. Its impossible for a RPI4 with a A72 even with ideal instructions to get 100 percent uops utilisation is in fact impossible.
Yes in IPC A72 is under half that of a A77. The clockspeed of a A77 also doubles compared to a A72. So to work out what a A77 is compared to a intel chip you need to quad the performance you are seeing out the RPI4 at least. Intel chips are not winning by enough.
I worked out your big mistake.
ARM cores are not hyperthreaded. So you only have 1 decoder engine and 1 thread this makes a big difference. You don't have the problem that means that you need to read the store que when doing a load. You don't need the complex load store structures when you don't have hyper-threading. Its for a funny reason. High speed register storage can only be made so big. Be it a hyperthreading x86 core or a single threaded arm core your max size for register storage is the same. Notice something arm has more free shadow registers so something is sent to store and some up coming operation is going to use it arm can leave the value in a shadow register.
atomsymbol requirement to get gain from complex load store setup. Does not happen in a arm as that is rewritten to store(X) use register that X was stored in instead of Load(X) so this skips the load(X) completely. Of course you cannot do that if you don't have the register storage space.store(X) load(X) pair are seen by the instruction window at the same time (aka "in the same clock").
Hyperthreading that starts in the alpha chips cause level of complexity and a lot more register space usage. This lead into having to have more complex load/store structures to cover for the fact you run short on register space. Yes having your loads read the outgoing store buffer or the reverse slows down your load store speeds.
A72 issues is
1) its not processing enough instructions per cycle because its rename system is too small.
2) its need a few more uops
3) its clock speed it too low.
The load store the design of the A77 and A78 is basically the same as the A72 the buffers have been made bigger due to more uops. That design does not cause any issues when you don't have hyperthreading. The ability for the load to read the outgoing store buffer is only required when you hyperthread resulting in having to store more state in registers so effectively running yourself out of register space storage.
Arm design the load store buffer sizes align to the number of uops the core has. How effectively those uops are used aligns to how much renaming of registers is possible. Register renaming directly controls the IPC per clock value.
Interesting point A77/A78 require a more expensive nm of production but power usage of a A72 at 1.5Ghz is the same as a A77/A78 at 3Ghz. So yes in theory if you could get a A77/A78 produced in the same soc design as what is on the RPI4 you could drop it on there and keep the complete board the same. Yes the outside mm squared of the silicon chip also stay the same between A77/A78 and a A72. So it is possible for someone to make a insanely fast RPI class board its just not cost effective yet to make them using A77/A78 cores yet.
There are many server grade chips of arm that expanded in the same way A77 and A78 have of course they are not arm A77 or A78 cores.
RPI4 is also still under performing for where it should be.
I can totally understand apple going arm.
1 arm cores that give the same performance as intel x86 chips are not power hungry.
2 apple cooler designs are commonly designed by a moron. Yes a laptop with fan that cools nothing apple in fact made that. They need cores than can be passively cooled to get past their hardware designer who are complete idiots at times.Comment
-
If I'm making a mistake it is not completely ignoring you.Originally posted by oiaohm View Post
Hyperthreading generally makes IPC worse, because you have two threads competing for resources (and that includes the instruction window, or the load-store queues).Comment
-
No its not the load-store queues where the problem. The biggest harm of Hyperthreading is running you out of register storage and that has knock on effects.Originally posted by vladpetric View Post
Originally posted by vladpetric View Post
Go read the original Mips based RENO paper. Original RENO does not do store-load bypassing. Original mips RENO does load elimination same way arm cores do.
RENO stands for RENaming Optimizer. "modified MIPS-R10000 register renaming mechanism" Direct quote out that paper.
Since the bit on there called Rename in the arm cores that is the RENO equal part. Interest point is that the Rename part of the arm design is older than the MIPS RENO and does the same things.
You see RENO mentioned when people are talking about Alpha and X86 expect they are now talking about this horrible thing in the load store buffers in store-load bypassing instead of in registers. Why are does the Alpha and x86 do RENO in the load store buffers simple they are hyper-threading they have run out of high speed register space.
Like it or not there are two basic designs for RENO.
1) MIPS/ARM design of RENO that is register based. This load elimination by storing value in shadow register as well as sending it out to be stored. The one in arm cores technically is not RENO its a older thing that does the same things 99.999% of the time there are a handful of corner cases that you can do that shows arm implementation is not a proper RENO but is the older beast.
2) Hyperthreading cores alpha/x86/powerpc you see something that is called RENO that is load/store buffer based. This is RENO that done by store-load bypassing in the load store buffer. Has to be done this way because you are out of register space to use as effective scratch pad.
Can you see the knock on effect of hyper-threading now. Something that for most effectiveness should be done in registers the RENO is forced out to the load store buffer area due to having hyper-threading. Its not the only form of optimisation that no longer ends up in the ideal location due to implementing hyper-threading so running your design low on register space.
Yes hyperthreading lowers IPC. Designs that take RENO done the way hyperthreading cores would do it also take a IPC hit because you are no longer getting the full advantage of RENO implemented in registers.
If you are the Vlad Petric from the original RENO paper you should have known it has absolutely nothing to-do with load-store buffers or store-load bypassing as it technically not either. Original RENO is a optimisation to eliminate as many uops as you can results in something that behaves as if you have a store-load bypass by instead eliminating different loads out of existence. Original RENO also makes add and other instructions pull the magic disappearing act.
The RENO you find on hyperthreaded cpus in the load store buffers is restricted to only effecting load/store operations. You start seeing in hyperthreaded cpus RENO implemented like twice once for general instructions and once for the load/stores in the load store buffer stuff.
The paper on memory bypassing not worth it is more than true. RENO is worth it but its not memory bypassing but instruction elimination. Instruction elimination is always going to help performance arm cores are already doing this.
Comment
-
I have three 4GB and also the new 8GB version of RPi. I don't think any of the the tests are RAM size limited (maybe by throughput).Originally posted by DihydrogenOxide View Post
Last time I used PTS as a benchmark (and to stress RPIs when overclocking them) , the answer regarding governor was - yes, it plays a role. Because it somehow shortens some lags between parts of the benchmark. I wildly guess it is related with new process creation. Some tests were some percents faster when using performance governor, the variance was definitely more predictable - less spread between runs.
RPi has some RTOS running under the hood, they've removed lots of unnecessary code from it, remains some code to manage frequency scaling/changing - this may also add latencies, because as I eerily remember, when I was running my realtime AD converter code on a RPI3 and the ondemand governor was active, I had some insanely long latencies sometimes. After I fixed the governor to performance, it was all under 123 us (so the real spread of nanosleep latency was between 67-123 us). Not tried it on a RPi4 yet. My bet - it may add some more latency besides Linux's latencies if you run ondemand governor. Maybe even some cache thrashing.
Right now, I test a RPi 4 8GB in a small Red Bull fridge using CooliPi ( http://www.coolipi.com ) with the 60mm Noctua fan, real temperatures vary between 1-10°C. I use MX-2 thermal paste from Arctic Cooling.
Two hours ago, I was testing it in a deep freeze unit of our main fridge between peas and carrots. Aside from the fact, that vcgencmd still has the temperature reporting bug (see here https://www.coolipi.com/Liquid_Nitrogen.html ) even after a year after we tested it with liquid Nitrogen, it overclocks well at 2147MHz. I bet the new 8GB versions are going to be good overclockers, because with RPi 4 4GB, more units I had rebooted when all of their cores were being loaded simultaneously. The testimony of the PMIC guilt is that some were stable at 1860MHz with over_voltage=2, but not at over_voltage=3 (reboot).
Single-core overclockability was relatively good, but when overloading it (by PTS for example), the integrated PMIC switcher couldn't supply enough current, hence a reboot came after 1.2V rail voltage drop came, which causes reset/reboot.
The 8GB version has at least one inductor around the PMIC different, but looks like it's for good. It's even smaller than the previous one. Maybe they increased the frequency? I have yet to see it with an oscilloscope.
To really use more RAM, it's necessary to go 64bit. I've installed Raspberry Pi OS 64bit (experimental), but PTS couldn't find some libraries, so the testing was somewhat incomplete. Now I'm trying it with Ubuntu 20.04 64bit (also contains the buggy vcgencmd, but kernel temperature reporting seems OK) at 2147MHz, using performance governor and all of this is in that small fridge. To keep temperatures the lowest, I use CooliPi 4B with that anecdotal 60mm Noctua fan on top of it (when idle, it has about 2.8°C higher temperature than ambient air).
To wrap it up - I had three RPi4 4GB overclocked to 1750, 1850 and 2000 MHz, respectively, and now a single new 8GB version overclocks directly to 2147MHz, albeit needing appropriate cooling.
My question to you, more knowledgable users is this: how can I get the runs of the same clocked RPis out of openbenchmarking.org database? And second, how (the hell) to name my overclocked runs, so that it's sane? I'm always confused when PTS asks 6 lines of descriptions at the beginning. Very confusing - I'm not familiar with it yet so sorry for an inconvenience.
I was a bit worried that finishing the PTS suite with an overclocked RPi at 2147MHz would require liquid Nitrogen (again - see my video, I don't have enough of it to pour the RPi for 6 hours again), but it seems that it's stable at mild temperatures around 10°C. Over_voltage=6 of course...Last edited by CooliPi; 17 August 2020, 12:53 PM.Comment

Comment