
 Tweet
Tweet
Is AMD using the very same buggy implementation, that OpenCL devs hate so much, for HSA? If so, hopefully they will fix it... or HSA itself will be an ugly mess.
-
-
HSA use of this feature is a short-term solution while we finish work on an open source HSAIL finalizer (HSAIL to HW ISA, ie shader compiler for HSA). The kernel driver and associated userspace library are already open, HSAIL runtime will be opened up next, and finalizer will be last. In the meantime we will be using this feature to provide an easy way to exercise the kernel driver and runtime code without having to hand-write GPU code or use any closed-source code.Originally posted by Meteorhead View Post
We have published code to compile an OpenCL kernel to HSAIL and run the resulting code through the HSAIL runtime, but most of that code is closed source at the moment.
This doesn't change anything re: coexisting with the Catalyst driver. Not sure what "ADM HW" means, was that supposed to be AMD ? This particular change is a stepping stone from an HSA perspective, not end game.Originally posted by Meteorhead View Post
The HSA stack itself, which we're shipping now as a mix of open and closed source, is primarily about enabling new-to-GPU languages including languages which were not designed around traditional GPU limitations the way OpenCL was. It's the standards effort and HSAF partnerships that drive enabling these languages on a wider range of devices, by providing a common runtime framework for language APIs that is available across many devices and many vendors.Test signatureComment
-
The Catalyst OpenCL implementation is just one of the language APIs that can potentially be supported over the HSA stack, but the HSA stack itself is generally new code. There will probably be some shared code in the finalizer though.Originally posted by asdfblah View PostTest signatureComment
-
-
Something like this...
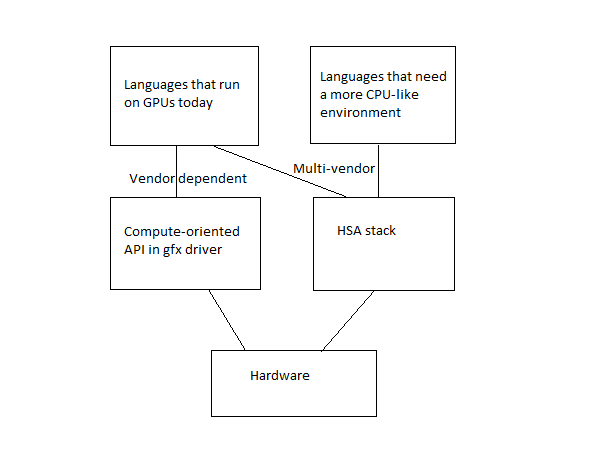
I used the term "multi-vendor" rather than "vendor-independent" since at the moment we only know that HSAF partners will be implementing the stack, but even so we still end up with a fair amount of leverage for work done on language APIs and related tools. Our HSA stack will be open source which should also help.Test signatureComment
-
Looking at this graph, what do you expect the perf cost to be to go through HSA instead of using a language with "direct access" to GPUs?Comment
-
@bridgman: Thank you for the info. So if I understand correctly, AMD intends on rewriting their various language frontends (HLSL, GLSL, ...) and runtimes to target a common compiler and runtime, that is the HSA finalizer and runtime. Is this correct? is HSAIL capable of serving all these scenarios, such as being able to provide extensions to various fixed function hardware needed to compile efficient DX shaders.
As being an academic user gravely struggling with manpower, I am mostly welcome to solutions that are "code once, run anywhere". I believe the best shot of HSA coming to the mainstream is to develop tools that are compatible with non-HSA member hardware. I know this is a pain and somewhat defeats the objective of HSA, however... if I'm not mistaken NVIDIA opened their CUDA API to be implemented by anyone. Creating a CUDA-compatible compiler that is able to produce not PTX, but HSAIL could be the greatest leap toward "stealing" users from those currently vendorlocked due to the excessive use of CUDA-only libraries and codebase. (Though giving an option to have the codebase unchanged and still run on HSA-enabled hardware might not be the best motivation. But hey, why not have CUDA as a source language for HSA?) Clamp ain't going to change the world so long it relies on the 3 year old OpenCL 1.1 implementation of NVIDIA. So long as NVIDIA does not care about the world outside CUDA, there is no real high-performance portable solution.
My question aimed on these kind of questions, those about the "bigger picture". Does the HSAF have plans of creating tools that are compatible with "competing" technologies? Does HSA bring about the age of being able to write graphics shaders and compute shaders in C++ and being able to link them together?Comment
-
Sort of... there are two compilers in a typical compute stack these days, one going from the shader programming language (eg C99 for OpenCL) to some kind of IR, and another going from that IR to HW instructions. The reason for the split is that the lower level compiler is used for a number of different API/language sets, each with a different upper level compiler.
Today the Catalyst OpenCL stack uses EDG front end plus LLVM back end to generate AMDIL (AMDIL is the common language between OpenGL, OpenCL, Direct3D etc..), then a lower level shader compiler converts AMDIL to HW instructions. When we run OpenCL over HSA the upper level compiler generates HSAIL instead of AMDIL and the HSAIL finalizer converts HSAIL to HW instructions.
The open source OpenCL stack is a bit different because the common language (at least for radeonsi) is LLVM IR, so the OpenCL stack uses Clang to generate LLVM IR then passes it to the shader compiler, bypassing the usual TGSI-to-LLVM IR step.
No plans to run graphics shaders (GLSL, HLSL) through HSAIL, although since both GL and DX have compute options built in these days that's not necessarily a simple black-or-white choice.Test signatureComment

Comment