 Tweet
Tweet
Code:
+ /* for (unsigned int i = 0x0120; i <= 0x013f; ++i) {
+ unsigned char output;
+ i8042_command(&output, i);
+ }*/
As a general rule, the more assumptions you have to make, the more likely things will eventually break.

+ /* for (unsigned int i = 0x0120; i <= 0x013f; ++i) {
+ unsigned char output;
+ i8042_command(&output, i);
+ }*/
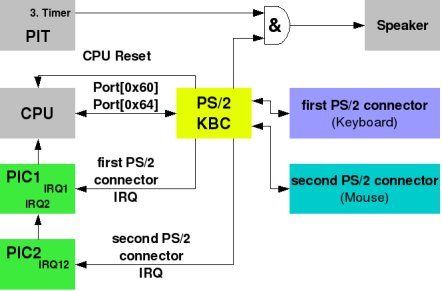

 (Well, that was just a chip on the controller which took fire).
(Well, that was just a chip on the controller which took fire).

Comment